Feature Selection Techniques dalam Machine Learning
11 March 2026
Updated: 11 March 2026
Feature selection adalah proses memilih hanya fitur (variabel input) yang paling penting untuk digunakan dalam model machine learning. Tujuannya adalah agar model bekerja lebih baik, mengurangi noise pada data, dan membuat hasil model lebih mudah dipahami.
Feature selection membantu untuk:
Menghapus fitur yang tidak relevan atau redundant
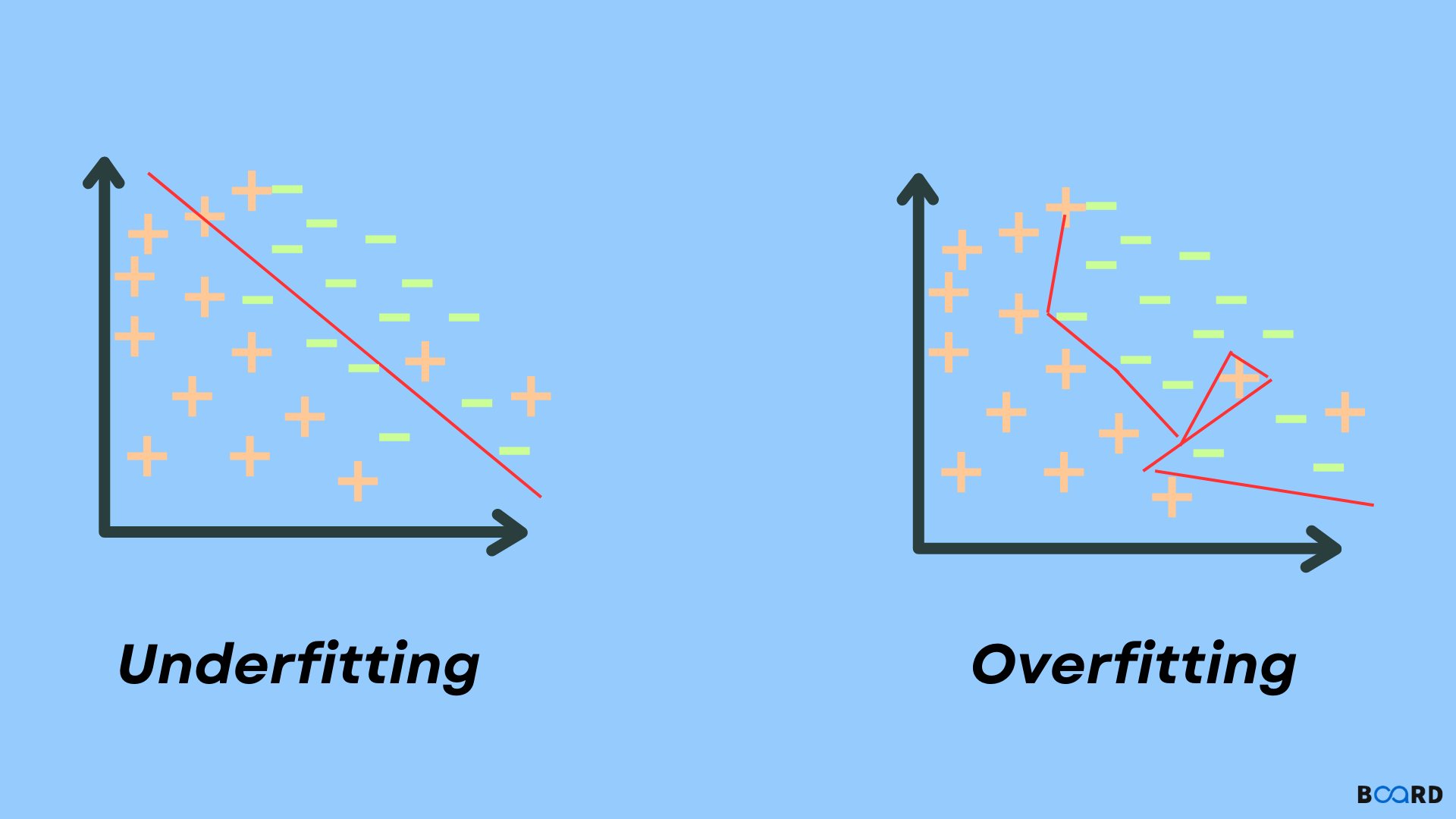
Meningkatkan akurasi model dan mengurangi overfitting
Mempercepat proses pelatihan model
Membuat model lebih sederhana dan mudah diinterpretasikan
Mengapa Feature Selection Diperlukan
Feature selection sangat penting dalam data science dan machine learning karena beberapa alasan berikut:
1. Meningkatkan Akurasi
Model akan belajar lebih baik jika dilatih hanya dengan fitur yang benar-benar penting.
2. Mempercepat Training
Semakin sedikit fitur yang digunakan, maka waktu komputasi menjadi lebih cepat.
3. Memudahkan Interpretasi
Jika jumlah fitur lebih sedikit, maka perilaku model lebih mudah dipahami.
4. Menghindari Curse of Dimensionality
Jika jumlah fitur terlalu banyak, kompleksitas model meningkat. Feature selection membantu mengurangi dimensi data sehingga model lebih stabil.
Jenis-Jenis Metode Feature Selection
Metode feature selection biasanya dibagi menjadi tiga kategori utama. Masing-masing memiliki kelebihan dan kekurangan tergantung pada kebutuhan analisis.
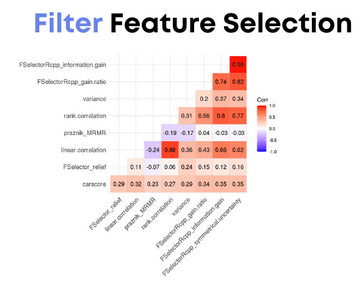
1. Filter Methods
Filter methods mengevaluasi setiap fitur secara independen terhadap target variable.
Fitur yang memiliki korelasi tinggi dengan target akan dipilih karena dianggap memiliki hubungan yang kuat untuk membantu prediksi.
Metode ini biasanya digunakan pada tahap preprocessing data untuk menghapus fitur yang tidak relevan berdasarkan uji statistik atau ukuran korelasi.
Teknik Filter yang Umum Digunakan
Information Gain
Mengukur seberapa besar pengurangan entropy ketika suatu fitur digunakan.Chi-Square Test
Menguji hubungan antara fitur kategorikal dengan target.Fisher Score
Memberi peringkat fitur berdasarkan kemampuan memisahkan kelas data.Pearson Correlation Coefficient
Mengukur hubungan linear antara dua variabel numerik.Variance Threshold
Menghapus fitur yang memiliki variansi sangat kecil.Mean Absolute Difference
Mirip dengan variance threshold tetapi menggunakan selisih absolut.Dispersion Ratio
Rasio antara mean aritmatika dan mean geometrik. Nilai tinggi menunjukkan fitur yang lebih informatif.Kelebihan
Cepat dan efisien untuk dataset besar
Mudah diimplementasikan
Tidak tergantung model sehingga bisa digunakan dengan berbagai algoritma machine learning
Kekurangan
Tidak mempertimbangkan interaksi antar fitur
Harus memilih metrik statistik yang tepat agar hasil optimal
2. Wrapper Methods
Wrapper methods menggunakan model machine learning untuk mengevaluasi kombinasi fitur yang berbeda.
Metode ini mencoba berbagai kombinasi subset fitur, lalu melihat bagaimana pengaruhnya terhadap performa model.
Proses ini biasanya berhenti ketika:
Performa model mulai menurun
Jumlah fitur yang diinginkan sudah tercapai
Teknik Wrapper yang Umum Digunakan
Forward Selection
Mulai dari tanpa fitur, kemudian menambahkan fitur satu per satu.Backward Elimination
Mulai dari semua fitur, lalu menghapus fitur yang paling tidak penting.Recursive Feature Elimination (RFE)
Menghapus fitur yang paling tidak penting secara bertahap.Kelebihan
Lebih optimal untuk model tertentu
Bisa menghasilkan performa lebih baik dibanding metode filter
Kekurangan
Sangat mahal secara komputasi
Berisiko overfitting jika terlalu menyesuaikan dengan satu model
3. Embedded Methods
Embedded methods melakukan seleksi fitur selama proses training model berlangsung.
Metode ini menggabungkan kelebihan filter dan wrapper karena seleksi fitur terjadi langsung di dalam proses pembelajaran model.
Teknik Embedded yang Umum Digunakan
L1 Regularization (Lasso)
Mempertahankan fitur yang memiliki koefisien tidak nol.Decision Tree dan Random Forest
Memilih fitur berdasarkan pengurangan impurity.Gradient Boosting
Memilih fitur yang paling mampu menurunkan error prediksi.Kelebihan
Efisien dan cukup akurat
Seleksi fitur dilakukan langsung oleh model
Kekurangan
Interpretasi lebih sulit
Tidak semua algoritma machine learning mendukung metode ini
Cara Memilih Metode Feature Selection yang Tepat
Pemilihan metode feature selection tergantung pada beberapa faktor:
1. Ukuran Dataset
Dataset besar → Filter methods lebih cepat
Dataset kecil → Wrapper methods bisa digunakan
2. Jenis Model
Beberapa model seperti Decision Tree atau Random Forest sudah memiliki seleksi fitur bawaan.
3. Interpretasi Model
Jika ingin memahami alasan pemilihan fitur, maka filter methods lebih mudah dijelaskan.
4. Sumber Daya Komputasi
Wrapper methods membutuhkan waktu komputasi yang lebih besar, sehingga perlu mempertimbangkan kapasitas komputer.
Kesimpulan
Feature selection membantu:
meningkatkan performa model
mengurangi kompleksitas data
mempercepat proses training
membuat model lebih mudah dipahami
Dengan memilih metode feature selection yang tepat, kita dapat menghasilkan model machine learning yang lebih efisien dan akurat.